This one confounds me and I've been playing with it for a while. Maybe you can reproduce it. This is how I discovered it.
I have two drives that are largely identical. For this testing, I made it so that Everything only indexes these two drives and no others.
I used the filter term: dupesize: !dupe:
Then I changed the term to: dupesize: dupe:
The same few files exist on both drives, but with !dupe: they'll show up on the one drive, and with dupe: they'll show up for the other drive (along with all the other dupes between both drives).
I exported the search results of both drives, with no filter terms, to an EFU file, loaded the EFU file, and this behavior goes away. The behavior is only present with normal drive indexing.
One of the drives is NTFS. The other drive is exFAT. None of the few files have any curious filename characters that the other thousand filenames do not also contain. Nothing special in common between these files pops out to me.
If you can't reproduce this effect, I can take a video demonstration.
Bug with dupe: not identifying filename matches
Re: Bug with dupe: not identifying filename matches
Oh, not sure that combinations of sizedupe: !dupe: or similar were particularly taken into consideration.
As it is, sizedupe: !dupe: will only NOT show files that have both the same size & the same name.
And for those that do display, that are both sizedupe: & !dupe:, it may not be determinable which one(s) will show up?
Or something like that.
Do something like this & see if you can make sense of it:
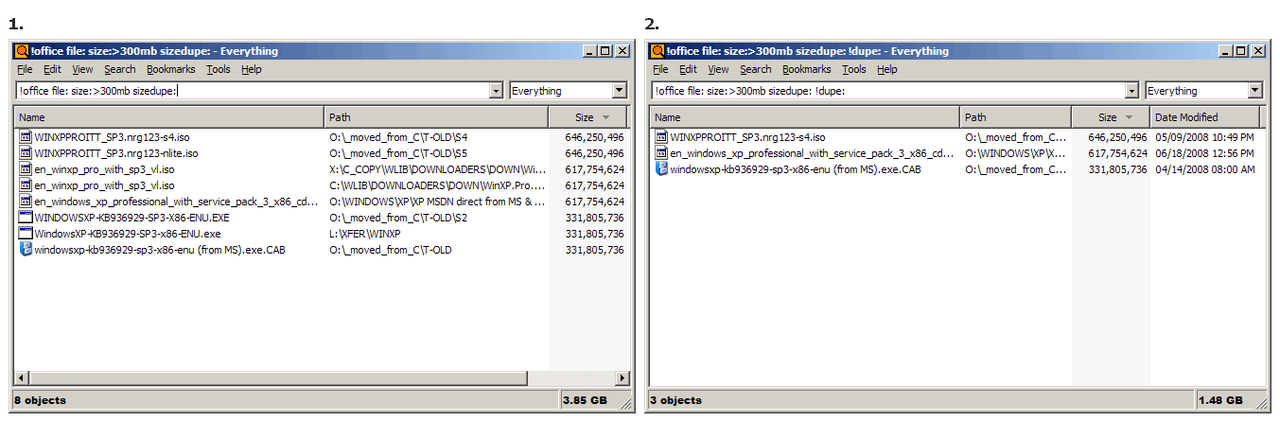
by size:
646, different names, out of 2 matches, so 1 appears
617, 3 matches, 2 with both same name & size, so !dupe: wipes them out, leaving the differently named file
331, same as 617, only difference is case difference between two of them
As it is, sizedupe: !dupe: will only NOT show files that have both the same size & the same name.
And for those that do display, that are both sizedupe: & !dupe:, it may not be determinable which one(s) will show up?
Or something like that.
Do something like this & see if you can make sense of it:
by size:
646, different names, out of 2 matches, so 1 appears
617, 3 matches, 2 with both same name & size, so !dupe: wipes them out, leaving the differently named file
331, same as 617, only difference is case difference between two of them
Re: Bug with dupe: not identifying filename matches
It does not seem that you have been able to reproduce my bug. All of the names listed in the second are properly !dupe:, while I have files that are properly dupe: but show up with !dupe:. I have also checked each of the names byte-for-byte.
The weird thing is that it behaves correctly if I export my database to EFU and then load it from there.
Could there be some hidden property like an 8.3 filename that differs, excess NUL character string terminators, that don't make it into the EFU and so don't afflict the results of dupe: ?
The weird thing is that it behaves correctly if I export my database to EFU and then load it from there.
Could there be some hidden property like an 8.3 filename that differs, excess NUL character string terminators, that don't make it into the EFU and so don't afflict the results of dupe: ?
Re: Bug with dupe: not identifying filename matches
The dupe functions find duplicates in the ENTIRE index, not the current results.
Use only one duplicate function at a time.
For the best results, use sizedupe: and sort by size descending.
If you wish to find duplicates in the current results:
Use only one duplicate function at a time.
For the best results, use sizedupe: and sort by size descending.
If you wish to find duplicates in the current results:
- In Everything, type in your search without a dupe function, for example:
!office file: size:>300mb - From the File menu, click Export....
- Change Save as type to EFU Everything File List.
- Choose a filename and click Save.
- From the File menu, click Open file list....
- Choose your EFU file list you saved earlier.
- Search with your duplicate function, eg:
sizedupe: - When you are finished with the results, close the file list:
- From the File menu, click Close file list.
Re: Bug with dupe: not identifying filename matches
I understand what you're saying, but as I stated above, I have already eliminated my "ENTIRE INDEX" to just the two specimen drives at hand. One drive being a backup of the other drive. One drive NTFS and the other exFAT.
I created an EFU of the entire index, no filtration, and the behavior mysteriously corrects itself when loading that EFU. The number of files in the natural index, and the EFU are identical, all files accounted for. The inverted dupe: behavior is corrected with the loaded EFU, but remains incorrect in the natural index.
If you read my comments above, I suspect there might be some hidden characters, like extra terminating NULs, that are causing the dupe mismatch. Could you check please?
Re: Bug with dupe: not identifying filename matches
Mixing sizedupe: and dupe: will not find files with the same size AND the same name.
Using both of these search terms together will find files that have the same size anywhere in the entire index and files that have the same name anywhere in the entire index.
A result is added when this condition is true for both sizedupe: and dupe:
It is possible the file shares the same size with another file and the name with a completely different file.
For example, you have the following files:
c:\abc.txt 1kb
c:\123.txt 1kb
d:\abc.txt 1mb
sizedupe: will find c:\abc.txt and c:\123.txt
dupe: will find c:\abc.txt and d:\abc.txt
sizedupe: and dupe: together will find all the above files, when you might expect it to not match anything.
dupe: will ignore case and diacritics!
For example:
Röyksopp.txt
royksopp.txt
are consider duplicates.
What is the search you are using and could you please give an example of the results and the results you expected?
Using both of these search terms together will find files that have the same size anywhere in the entire index and files that have the same name anywhere in the entire index.
A result is added when this condition is true for both sizedupe: and dupe:
It is possible the file shares the same size with another file and the name with a completely different file.
For example, you have the following files:
c:\abc.txt 1kb
c:\123.txt 1kb
d:\abc.txt 1mb
sizedupe: will find c:\abc.txt and c:\123.txt
dupe: will find c:\abc.txt and d:\abc.txt
sizedupe: and dupe: together will find all the above files, when you might expect it to not match anything.
dupe: will ignore case and diacritics!
For example:
Röyksopp.txt
royksopp.txt
are consider duplicates.
What is the search you are using and could you please give an example of the results and the results you expected?