Hello,
first of all: Thank you for this amazing software! It's one the applications I miss most on other operating systems. That's why I started to develop an alternative for Linux and I have a question regarding some of the data structures you use.
Everything search has a pretty small memory footprint, so I guess you only keep the file and directory names in memory and build the path names only when requested (e.g. for display or sorting)? This makes me wonder how you do that, while still maintaining this incredible performance when doing sub string searching. Is it a B+ tree?
Thanks!
What data structures does ES use internally?
Re: What data structures does ES use internally?
Just an update in case someone is interested in this. My current solution looks like that:
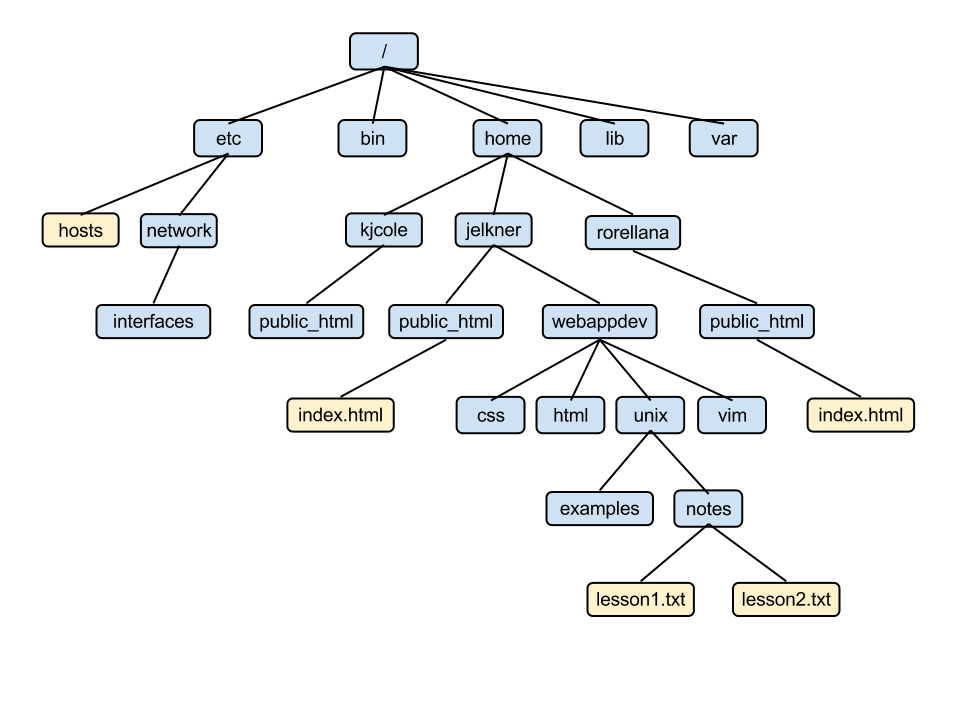
The Database is stored in memory as a B-Tree which basically looks like that:http://www.openbookproject.net/tutorial ... ryTree.png
That's quite memory efficient, since I don't need to hold full path names in memory multiple times, but can build them when I need them by walking upwards the tree. Modifications to the tree (delete a folder etc.) are also really efficient. However traversing the tree with multiple threads to perform a search is quite slow (e.g. it's really hard to balance the load between multiple threads), that's why I'm also building multiple arrays (all sorted differently) with pointers to all the nodes in the tree on which I perform the search. Each search thread has a dedicated area in the arrays on which it can perform a search, with great access times.
In terms of memory consumption and performance I'm now getting similar results as Everything -- still a few milliseconds slower but I guess Everything has been optimized greatly.
Kind regards
Edit: And again thanks for that great application and the inspiration to do something similar
The Database is stored in memory as a B-Tree which basically looks like that:http://www.openbookproject.net/tutorial ... ryTree.png
{kind=link}
That's quite memory efficient, since I don't need to hold full path names in memory multiple times, but can build them when I need them by walking upwards the tree. Modifications to the tree (delete a folder etc.) are also really efficient. However traversing the tree with multiple threads to perform a search is quite slow (e.g. it's really hard to balance the load between multiple threads), that's why I'm also building multiple arrays (all sorted differently) with pointers to all the nodes in the tree on which I perform the search. Each search thread has a dedicated area in the arrays on which it can perform a search, with great access times.
In terms of memory consumption and performance I'm now getting similar results as Everything -- still a few milliseconds slower but I guess Everything has been optimized greatly.
Kind regards
Edit: And again thanks for that great application and the inspiration to do something similar
Re: What data structures does ES use internally?
There was some talk a few years ago about how Everything works in an irc channel. Mind you, I barely/vaguely remember the discussion.
One person said Everything stores all the file/folder names in an array. Have some form of tree structure, maybe some version of B-Tree. The tree among other things contain the index of where the name is in the array.
Having the names in an array means files or folders with the same name will all point to the same index.
There were also some talk about skip list map but I've forgotten the context of it.
I have no idea if this is how Everything do it.
Your tool. Will you open source it?
One person said Everything stores all the file/folder names in an array. Have some form of tree structure, maybe some version of B-Tree. The tree among other things contain the index of where the name is in the array.
Having the names in an array means files or folders with the same name will all point to the same index.
There were also some talk about skip list map but I've forgotten the context of it.
I have no idea if this is how Everything do it.
Your tool. Will you open source it?